ഗുണ്ടർട്ട് ലെഗസി പദ്ധതിയുമായി ബന്ധപ്പെട്ട്, ട്യൂബിങ്ങൻ ഗുണ്ടർട്ട് ശേഖരത്തിലെ രേഖകൾ ഡിജിറ്റൈസ് ചെയ്ത് റിലീസ് ചെയ്യുമ്പോൾ, പൊതുവിടത്തിലേക്ക് വരുന്ന ഓരോ രേഖയെ പറ്റിയും ഞാൻ അക്കാലത്ത് പൊസ്റ്റുകൾ എഴുതിയിരുന്നു. പദ്ധതി തീർന്നതിനു ശെഷം ഈ രേഖകൾ ട്യൂബിങ്ങൻ ഡിജിറ്റൽ ലൈബ്രറിക്കു പുറമെ വിക്കിഗ്രന്ഥശാല, ആർക്കൈവ്.ഓർഗ് തുടങ്ങിയ ഇടങ്ങളിൽ കൂടി അപ്ലൊഡ് ചെയ്തു. ഈ കാര്യങ്ങളെ പറ്റി ഒക്കെ വിശദമായി വിശദമായി ഞാൻ ഈ ബ്ലോഗ് പോസ്റ്റിൽ സൂചിപ്പിച്ചിട്ടൂണ്ട്. എന്നാൽ വിവിധ ഇടങ്ങളിലായി ചിതറിക്കിടക്കുന്ന വിവരങ്ങൾ എല്ലാം കൂടി സമാഹരിച്ച് ലഭ്യമാക്കാൻ എനിക്കു കഴിഞ്ഞിരുന്നില്ല. എന്റെ കുറച്ചു സുഹൃത്തുക്കൾ കൂടെ സഹായിച്ചതിനാൽ ഇപ്പോൾ ആ പ്രശ്നം പരിഹരിച്ചു.
ഗുണ്ടർട്ട് ലെഗസിയിൽ കൈകാര്യം ചെയ്ത മലയാള രേഖകളുടെ വിവരങ്ങൾ എല്ലാം ചേർത്ത് ഇപ്പോൾ ഒരു സ്പ്രെഡ് ഷീറ്റ് നിർമ്മിച്ചിരിക്കുന്നു. പലയിടത്തായി ചിതറിക്കിടന്ന വിവരങ്ങൾ കോർത്തെടുത്ത് ഇങ്ങനെ ഒരു സ്പ്രെഡ് ഷീറ്റ് നിർമ്മിക്കാനും അത് ഇന്നത്തെ നിലയിലേക്ക് കൊണ്ടു വരാനും എന്നെ താഴെ പറയുന്ന മുന്നു പേർ സഹായിച്ചു.
ഈ മൂന്നു പേരോടുമുള്ള നന്ദിയും കടപ്പാടും അറിയിക്കട്ടെ.
ഈ ഗൂഗിൾ സ്പ്രെഡ് ഷീറ്റിൽ താഴെ പറയുന്ന അഞ്ച് വർഷീറ്റുകൾ ഉണ്ട്
അച്ചടി പുസ്തകങ്ങൾ – ലെറ്റർ പ്രസ്സ് – (യൂണിക്കോഡിലാക്കിയത്)
അച്ചടി പുസ്തകങ്ങൾ – ലെറ്റർ പ്രസ്സ് – (യൂണിക്കോഡിലാക്കാത്തത്)
കല്ലച്ചിൽ അച്ചടിച്ച പുസ്തകങ്ങൾ
കൈയെഴുത്ത് രേഖകൾ
താളിയോലകൾ
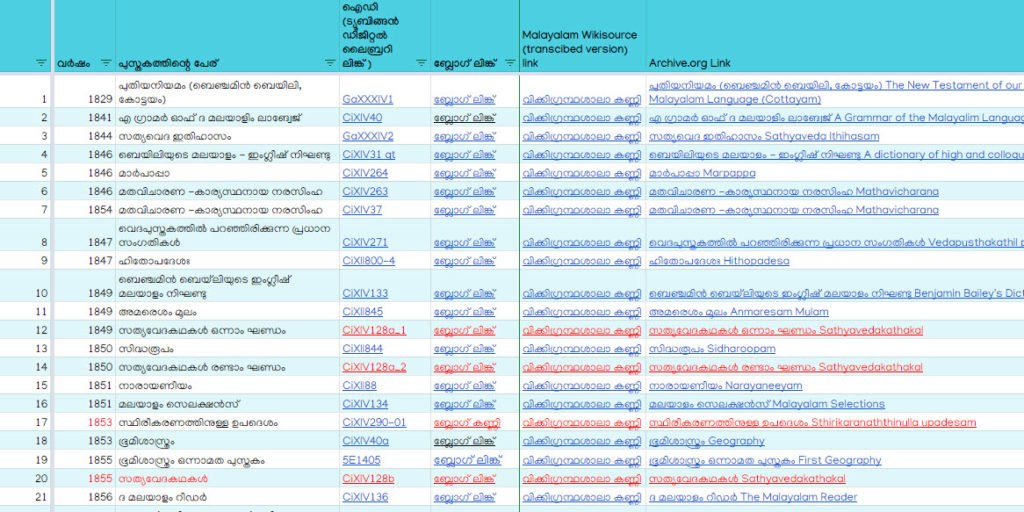
ഓരോ രേഖയെ പറ്റിയും താഴെ പറയുന്ന മെറ്റാ ഡാറ്റ ലഭ്യമാണ്”
അച്ചടിച്ച/രേഖപ്പെടുത്തപ്പെട്ട വർഷം
പുസ്തകത്തിന്റെ പേര്
രേഖയുടെ ട്യൂബിങ്ങൻ കാറ്റലോഗ് ഐഡിയും ഡിജിറ്റൽ ലൈബ്രറി ലിങ്കും
രേഖ റിലീസ് ചെയ്തപ്പോൾ ഞാൻ എഴുതിയ ബ്ലോഗ് പോസ്റ്റിലേക്കുള്ള ലിങ്ക്
രേഖയുടെ വിക്കിഗ്രന്ഥശാല ലിങ്ക്
രേഖയുടെ Archive.org ലിങ്ക്
ഇതിൽ യൂണിക്കോഡിലാക്കാത്ത രേഖകൾക്ക് വിക്കിഗ്രന്ഥശാല ലിങ്ക് ലഭ്യമല്ല എന്നത് ശ്രദ്ധിക്കുമല്ലോ.
പട്ടിക ഗൂഗിൾ ഷീറ്റായി നേരിട്ടു ആക്സെസ് ചെയ്യാൻ ഈ ലിങ്കിൽ അമർത്തുക. ഗൂഗിൾ ഷീറ്റിൽ എത്തി കഴിഞ്ഞാൽ അതിലെ Data > Filter Views > Create Temporary Filter Views > Click ▼ in a Column Title > Select Relevant Values എന്ന ഓപ്ഷൻ ഉപയോഗിച്ച് പല തരത്തിൽ നിങ്ങൾക്കു പട്ടികയിലെ പുസ്തകങ്ങൾ ഫിൽറ്റർ ചെയ്യാം. ആവശ്യമെങ്കിൽ പട്ടികയുടെ കോപ്പിയെടുക്കുകയും പല തരത്തിൽ പുനരുപയോഗിക്കുകയും ചെയ്യാം.
രേഖകൾ എല്ലാം ഒരുമിച്ചു കിട്ടാനും, അതിൽ നിന്ന് വിവിധ ഉപപട്ടികകൾ നിർമ്മിക്കാനും, മറ്റു കാറ്റലോഗുകൾ നിർമ്മിക്കാനും, ഗവേഷണാവശ്യങ്ങൾക്കും ഒക്കെ ഈ പട്ടിക പ്രയോജനപ്പെടും. ഈ പട്ടികകൾ ഈ മാസ്റ്റർ പട്ടികയുടെ ഒരു ഉപപട്ടിക മാത്രമാണ് എന്നത് ശ്രദ്ധിക്കുമല്ലോ.
ഞങ്ങൾ മൂന്നുപേരും (സിബു സി.ജെ., സുനിൽ വി.എസ്., ഷിജു അലക്സ്) ചേർന്ന് എഴുതി മലയാളം റിസർച്ച് ജർണലിന്റെ 12-ാം വാല്യം രണ്ടാമത്തെ ലക്കത്തിൽ (2019 മേയ് – ഓഗസ്റ്റ്) പ്രസിദ്ധീകരിച്ച, ഞങ്ങളുടെ മൂന്നാമത്തെ പ്രബന്ധം പൊതുവായി പങ്കു വെക്കുന്നു. ഈ പ്രബന്ധത്തിൽ ഞങ്ങൾ കേരളത്തിലെ ആദ്യത്തെ തദ്ദേശീയ അച്ചുകൂടങ്ങളിൽ ഒന്നായിരുന്ന വിദ്യാവിലാസം അച്ചുകൂടം, അതുമായി ബന്ധപ്പെട്ട വ്യക്തികളായ അരുണാചലമുതലിയാർ, കാളഹസ്തിയപ്പ മുതലിയാർ തുടങ്ങിയ സംഗതികൾ ആണ് കൈകാര്യം ചെയ്യുന്നത്.
പ്രബന്ധത്തിന്റെ തലക്കെട്ട് ചതുരങ്കപട്ടണം അരുണാചലമുതലിയാരുടെ വിദ്യാവിലാസം അച്ചുകൂടം എന്നാകുന്നു. ഞങ്ങളുടെ അന്വേഷണത്തിലൂടെ ലഭ്യമായ തെളിവുകൾ ഉപയോഗിച്ച് ചരിത്രപുസ്തകങ്ങളിൽ വിദ്യാവിലാസം പ്രസ്സിനെ പറ്റി രേഖപ്പെടുത്തിയിരിക്കുന്ന ചില വസ്തുതകളെ ഞങ്ങൾ പുനഃപരിശോധിക്കുന്നു. ഒപ്പം വിദ്യാവിലാസം പ്രസ്സിന്റെ പിൽക്കാല ചരിത്രവും അനാവരണം ചെയ്യാൻ ശ്രമിക്കുന്നു.
വില്വംപുരാണം എന്ന പുസ്തകത്തിന്റെ മെറ്റാഡാറ്റയുമായി ഈ പുസ്തകത്തിലെ മെറ്റാ ഡാറ്റ താരതമ്യം ചെയ്യുംപ്പോൾ ഞാൻ കണ്ട ഒരു പ്രത്യേകത അച്ഛനാരാ മോനാരാ എന്ന് സംശയമായി പോകുന്ന സ്ഥിതി ആയി എന്നതാണ്. വില്വംപുരാണത്തിൽ ചതുരംകപട്ടണം കാളഹസ്തിയപ്പ മുതലിയാർ അവർകളുടെ മകൻ അരുണാചല മുതലിയാർ വിദ്യാവിലാസം അച്ചുകൂടത്തിന്റെ ഉടമസ്ഥൻ ആവുമ്പോൾ, ഈ കൃതിയിൽ അത് ചതുരംകപട്ടണം അരുണാചല മുതലിയാരുടെ മകൻ കാളഹസ്തിയപ്പ മുതലിയാർ ആകുന്നു. ഇത്തരത്തിൽ ഒരു ആശയക്കുഴപ്പം എങ്ങനെ ഉളവായി എന്ന് അറിയില്ല.
ദെവിമാഹാത്മ്യം എന്ന പുസ്തകത്തിനു മുൻപ് റിലീസ് ചെയ്ത വില്വംപുരാണം എന്ന പുസ്തകത്തിന്റെ സ്കാൻ റിലീസ് ചെയ്തപ്പോൾ എഴുതിയ ഒരു പോസ്റ്റ് ഇവിടെ കാണാം. ദെവിമാഹാത്മ്യം എന്ന പൊസ്റ്റിൽ ഞാൻ എഴുതിയ മുകളിലെ പ്രസ്താവനയ്ക്കു മറുപടിയായി, എന്റെ സുഹൃത്ത് കൂടെയായ അനൂപ് നാരായണൻ ചാറ്റിൽ ഇങ്ങനെ ചോദിച്ചു
മകന്റെ മകന് മുത്തച്ഛന്റെ അതേ പേരിടുന്ന പതിവ് ചില സമുദായങ്ങൾക്കിടയിലുണ്ട്. ഇനി അങ്ങനെ ആയിരിക്കുമോ?
ആ സമയത്ത് ഇതിനെ പറ്റി “ഒരു ഊഹവും ഇല്ല“ എന്ന മറുപടി ആണ് ഞാൻ പറഞ്ഞത്. അത് അങ്ങനെ വിട്ടു.കാരണം ആ സമയത്ത് ഞാൻ ട്യൂബിങ്ങൻ രേഖകൾ ഓരോന്നായി റിലീസ് ചെയ്യുന്ന തിരക്കിലായിരുന്നു.
ഞങ്ങളുടെ അന്വേഷണം തുടങ്ങുന്നു
അല്പ മാസങ്ങൾക്ക് ശേഷം വിദ്യാവിലാസം കല്ലച്ചുകൂടത്തിൽ നിന്നുള്ള അമരസിംഹം എന്ന പുസ്തകം ഞാൻ കണ്ടെടുത്തു. (ഈ പുസ്തകം താമസിയാതെ റിലീസ് ചെയ്യാം). അതിൽ രേഖപ്പെടുത്തിയിരിക്കുന്ന വിദ്യാവിലാസത്തിന്റെ കല്ലച്ചുകൂടത്തെ പറ്റിയുള്ള വിവരം ഞങ്ങളെ അത്ഭുതപ്പെടുത്തി. കെ.എം. ഗോവിയോ മറ്റു അച്ചടി ചരിത്രകാരന്മാരോ രേഖപ്പെടുത്താതെ ഇരുന്ന ഒരു സംഗതി ആണത്. ഏതാണ്ട് അതേ സമയത്ത് തന്നെ ഹെൻറി ബേക്കർ ജൂനിയരുടെ മൂണ്ടക്കയത്തെ കല്ലച്ചുക്കൂടത്തെ പറ്റിയുള്ള പ്രബന്ധത്തിന്റെ അവസാന മിനുക്കു പണിയിലായിരുന്നു ഞങ്ങൾ. അതിനാൽ പല കാര്യങ്ങളും കൂട്ടി യോജിപ്പിക്കാൻ ഞങ്ങൾക്കായി.
ട്യൂബിങ്ങനിൽ നിന്ന് ഓരോ വിദ്യാവിലാസം പുസ്തകം റിലീസ് ചെയ്യുമ്പോഴും ഞങ്ങൾ വിട്ടു പൊയ കണ്ണികൾ പൂരിപ്പിക്കുകയായിരുന്നു. അതിൽ വഴിത്തിരിവായത് ട്യൂബിങ്ങനിൽ നിന്നു വന്ന 1866ലെ ബാസൽ മിഷൻ പഞ്ചാംഗത്തിൽ കണ്ട കോഴിക്കോട് മുൻസിഫിന്റെ പട്ടിക ആയിരുന്നു. ആ തെളിവ് കിട്ടിയതോടെ ഇതുമായി ബന്ധപ്പെട്ട എല്ലാ വശത്തേക്കും ഞങ്ങളുടെ തിരച്ചിൽ വ്യാപിപ്പിച്ചു.ഞങ്ങളുടെ അന്വേഷണം ഊർജ്ജിതമായി.
വിദേശ ലൈബ്രറികളിൽ നിന്നു കിട്ടിയ തെളിവുകൾ
ലേഖകരിൽ ഒരാളായ സിബു താമസിക്കുന്നത് ലണ്ടനിൽ ആയതിനാൽ ബ്രിട്ടീഷ് ലൈബ്രറി അടക്കമുള്ള ലണ്ടൻ ലൈബ്രറികൾ പരിശോധിക്കാൻ ഞങ്ങൾക്കായി.
കേംബ്രിഡ്ജ് യൂണിവേഴ്സിറ്റി ലൈബ്രറിയിലെ ചില രേഖകൾ പരിശോധിക്കാൻ ഞങ്ങളെ സഹായിച്ചത് പ്രശസ്ത ഇൻഡോളജിസ്റ്റായ ഓഫിറ ഗമേലിയേലായാണ്. അതിനു വേണ്ടി അവർ അവരുടെ ജോലി സ്ഥലത്ത് നിന്ന് കേംബ്രിഡ്ജിൽ ഞങ്ങൾക്ക് വേണ്ടി പോയി രേഖകൾ പരിശൊധിക്കുകയായിരുന്നു.
കർണ്ണാടകയിൽ നിന്നുണ്ടായ തിരിച്ചടി
അരുണാചല മുതലിയാരുടെ പിൽക്കാല ജീവിതം തപ്പി മൈസൂരിലും ബാംഗ്ലൂരിലും കർണ്ണാടക ആർക്കൈവ്സ് തപ്പാൻ പോയ എന്നെ റിസർച്ച് സ്കോളർ അല്ല പേരിൽ രണ്ടിടത്തും പ്രവേശനം നിഷേധിച്ചു. ഞാനും എന്റെ സഹപാഠിയായ കർണ്ണാടക സ്വദേശി ഡോ: ശിവലിംഗസ്വാമിയും കൂടി ഇതിനു വേണ്ടി മൈസൂരിൽ കുറച്ചധികം കറങ്ങി. പക്ഷെ ഫലം ഉണ്ടായില്ല.
ഇതുമായി ബന്ധപ്പെട്ട എന്റെ വിഷമം സോഷ്യൽ മീഡിയയിൽ ഞാൻ പങ്കു വെച്ചപ്പോൾ എന്റെ ചില സുഹൃത്തുക്കൾ വഴി കർണ്ണാടക കേഡറിലുള്ള ഒരു മലയാളി ഐ എ എസ് ഓഫീസർ സഹായിക്കാൻ മുന്നോട്ട് വന്നെങ്കിലും, ഇതിനു വേണ്ടി എന്റെ പ്രവർത്തി ദിനങ്ങൾ പിന്നേം നഷ്ടമാകും എന്നതിനാൽ അതിനു പിന്നെ മുതിർന്നില്ല. അതിനാൽ അത്തരം സംഗതികൾ തുടർ ഗവെഷണത്തിനു വിട്ടു.
കേരള സർക്കാർ സ്ഥാപനങ്ങളുടെ സഹകരണം
2012-2014ൽ ഞങ്ങൾ ചന്ദ്രക്കല: ഉത്ഭവവും പ്രയോഗവും എന്ന പ്രബന്ധം എഴുതുമ്പോൾ കേരളത്തിലെ സ്ഥാപനങ്ങൾ ഒന്നും ഞങ്ങളോട് സഹകരിച്ചിരുന്നില്ല. എന്നാൽ ഇപ്പോൾ കേരള സ്റ്റേറ്റ് ആർക്കൈവ്സും, കേരള സാഹിത്യ അക്കാദമിയും ഞങ്ങളോട് സഹകരിച്ചു. ഞങ്ങൾ ചൊദിച്ച ചോദ്യങ്ങൾക്ക് ഉത്തരം തരികയും നേരിട്ട് രേഖകൾ പരിശോധിക്കാൻ സഹായിക്കുകയും ചെയ്തു. അവിടെ നിന്ന് പുരാതനരേഖകൾ ഒന്നും കണ്ടെടുക്കാൻ കഴിഞ്ഞില്ലെങ്കിലും പ്രബന്ധത്തെ സഹായിക്കുന്ന ചില റെഫറൻസുകൾ ഞങ്ങൾക്ക് ഈ സ്ഥാപനങ്ങളിൽ നിന്ന് ലഭിച്ചു.
ഈ പ്രബന്ധത്തിന്റെ വിവരശേഖരണത്തിനായി ഞാൻ ഒരു ദിവസം കോഴിക്കോട്ടെ റീജിനൽ ആർക്കൈവ്സ് സന്ദർശിച്ച് ചില രേഖകൾ പരിശോധിച്ചു. കോഴിക്കോട് റോബിൻസൻ റോഡിലും (ഇപ്പോൾ കെ.പി. കേശവമേനോൻ റോഡ്) മറ്റും വിദ്യാവിലാസത്തിന്റെ അവശിഷ്ടങ്ങൾ തേടി കറങ്ങി. എന്റെ ഈ ഊരു തെണ്ടലിനു അബ്ദുൾ ലത്തീഫ് മാഷ് വളരെ സഹായിച്ചു.
ചെറായി രാമദാസിന്റെ സഹായം
സ്വതന്ത്ര ഗവേഷകനായ ശ്രീ ചെറായി രാമദാസ് താൻ കണ്ടെടുത്ത മിതവാദിമാസികയുടെ ആദ്യലക്കത്തിന്റെ കാര്യം ഫേസ് ബുക്കിൽ പോസ്റ്റ് ചെയ്തപ്പോൾ തന്നെ ഞാൻ ശ്രദ്ധിച്ചിരുന്നു. ഇപ്പോൾ ഈ പ്രബന്ധത്തിനായി പ്രസ്തുത ഫോട്ടോകൾ ഞാൻ അഭ്യർത്ഥിച്ചപ്പോൾ തന്നെ അദ്ദേഹം മെയിൽ ചെയ്തു തന്നു. അത് ഈ പ്രബന്ധത്തിനു വലിയ മുതൽക്കൂട്ടയി എന്നത് പ്രബന്ധം വായിക്കുമ്പോൾ മനസ്സിലാകും.
സുഹൃത്തുക്കളുടെ സഹായം
പ്രബന്ധവുമായി ബന്ധപ്പെട്ട ചില നിർണ്ണായിക തെളിവുകൾ കണ്ടെടുക്കാൻ വിനിൽ പോളൂം, മനോജ് എബനെസറും, എതിരൻ കതിരവനും സഹായിച്ചു. അക്കാദമിക് സർക്കിളിനു പുറത്ത് നിൽക്കുന്ന ഞങ്ങൾക്ക് ഒട്ടേറെ പരിമിതികളെ അതിജീവിച്ചു വേണം രെഖകളിലേക്ക് എത്താൻ. അതിനാൽ ഇന്ന രേഖ തപ്പിയെടുക്കാൻ സഹായിക്കാമോ എന്ന് ചോദിക്കുമ്പോൾ അതിനു തയ്യാറായ സുഹൃത്തുക്കൾ ഉണ്ടാകുന്നത് വലിയ ഭാഗ്യമാണ്.
ഡോ: ബാബു ചെറിയാനോടുള്ള കടപ്പാട്
ലേഖനത്തിന്റെ ചില സൂചനകൾ കിട്ടിയപ്പോൾ തന്നെ ഞങ്ങൾ ഈ വിഷയം ബാബു ചെറിയാൻ സാറുമായി ചർച്ച ചെയ്തിരുന്നു. അദ്ദേഹം ഓരോ ഘട്ടത്തിലും തന്ന നിർദ്ദേശങ്ങൾ ലേഖനത്തെ വികസിപ്പിക്കുന്നതിനു ഞങ്ങളെ സഹായിച്ചു. ലേഖനത്തിന്റെ പീർ റിവ്യൂവും അദ്ദേഹം തന്നെയാണ് ചെയ്തത്. വാസ്തവത്തിൽ ഞങ്ങൾ എഴുതുന്ന പ്രബന്ധത്തിന്റെ വിഷയത്തിൽ അദ്ദേഹത്തിനുള്ള താല്പര്യം, പ്രബന്ധം മെച്ചപ്പെടുത്തുന്നതിനു ഞങ്ങൾക്കു വളരെ സഹായം ആയിരുന്നു.
മറ്റു സംഗതികൾ
തലശ്ശേരി വിദ്യാവിലാസത്തിന്റെ വിവരശേഖരണം ബുദ്ധിമുട്ടായിരുന്നു. ജഗന്നാഥക്ഷേത്രവുമായി ബന്ധപ്പെട്ടെ ഒരു സുവനീറിൽ തലശ്ശേരി വിദ്യാവിലാസത്തെ പറ്റി ഒരു കുറിപ്പ് ഉണ്ട് എന്ന് ഒരാൾ പറഞ്ഞു എങ്കിലും അത് ഞങ്ങൾക്ക് കിട്ടിയില്ല. അതിനാൽ അതൊന്നും ഞങ്ങൾക്ക് ഇതിന്റെ റെഫറൻസിൽ ചേർക്കാൻ പറ്റിയില്ല.
വിദ്യാവിലാസത്തിന്റെ പിൽക്കാല ഉടമസ്ഥരിൽ ഒരാളായ എൽ.എസ്. രാമയ്യരുടെ ബന്ധുക്കളെ കണ്ടെത്താനായത് ഒരു നേട്ടമായിരുന്നു. പക്ഷെ ഒരു പരിധിക്കപ്പുറം വിവരം അവരിൽ നിന്ന് കിട്ടിയില്ല. എൽ.എസ്. രാമയ്യർ പാലക്കാട് ലക്ഷ്മിനാരായണപുരം സ്വദേശി ആയിരുന്നു. അവിടുന്ന് അദ്ദേഹം കോഴിക്കോട്ടേക്കും പിന്നീട് ചെന്നെയിലേക്കും പോയി. അദ്ദേഹത്തിന്റെ ചെറുമകനായ ജയറാം അമൃത് ഇപ്പോൾ സിംഗപ്പൂരിലേക്ക് കുടിയേറി.
ഉപസംഹാരം
ആധുനിക മലയാള അച്ചടിയുടെ ചരിത്രത്തിൽ നിർണ്ണായികമായ സ്വാധീനം ചെലുത്തി സുദീർഘമായ ഒന്നേകാൽ നൂറ്റാണ്ടോളം പ്രവർത്തിച്ച വിദ്യാവിലാസം അച്ചുകൂടത്തിന്റെ ചരിത്രം കുറേയൊക്കെ ഡോക്കുമെന്റ് ചെയ്യാൻ കഴിഞ്ഞതിൽ ഞങ്ങൾ കൃതാർത്ഥരാണ്. ഇതുമായി ബന്ധപ്പെട്ട തുടർ ഗവേഷണത്തിനു ഈ പ്രബന്ധം വഴിമരുന്നാകും എന്ന പ്രതീക്ഷയോടെ ഈ പ്രബന്ധം ഞങ്ങൾ പൊതുജന സമക്ഷം വെക്കുന്നു.
ചതുരങ്കപട്ടണം അരുണാചലമുതലിയാരുടെ വിദ്യാവിലാസം അച്ചുകൂടം എന്ന പ്രബന്ധം ഓൺലൈനായി വായിക്കാൻ ഇവിടെ സന്ദർശിക്കുക. ഡൗൺലൊഡ് ചെയ്യാൻ ഈ കണ്ണി ഉപയോഗിക്കുക.
കഴിഞ്ഞ അഞ്ചിലധികം വർഷങ്ങളായി നിരവധി രാജ്യങ്ങളീൽ (പ്രധാനമായും ജർമ്മനി, ഇന്ത്യ) ഇരുന്നു 250ൽ അധികം പ്രവർത്തകർ കൂട്ടായി നടത്തിയ ഗുണ്ടർട്ട് ലെഗസി പ്രൊജക്ട് എന്ന പദ്ധതിയുടെ വിശദാംശങ്ങളെ പറ്റി ഇതിനകം എല്ലാവർക്കും അറിവുള്ളത് ആണല്ലോ. പദ്ധതിയെ പറ്റി എന്റെ അനുഭവക്കുറിപ്പ് ഇതിനകം പ്രസിദ്ധീകരിച്ചു കഴിഞ്ഞതാണ്. അത് ഇവിടെ കാണാം.
സ്കാനുകൾ എല്ലാം പുറത്ത് വരികയും ഗുണ്ടർട്ട് പോർട്ടൽ ഔദ്യോഗികമായി റിലീസ് ചെയ്യുകയും ചെയ്തു എങ്കിലും പദ്ധതിയുമായി ബന്ധപ്പെട്ട സന്നദ്ധപ്രവർത്തകരുടെ പണികൾ അവസാനിച്ചിട്ടില്ല.
യൂണിക്കോഡിലാക്കിയ പുസ്തകങ്ങളുടെ സ്കാനുകൾ വിക്കിമീഡിയ കോമൺസിലേക്കും ആർക്കൈവ്.ഓർഗിലേക്കും അപ്ലൊഡ് ചെയ്യുക, യൂണിക്കോഡ് പതിപ്പ് മലയാളം വിക്കിഗ്രന്ഥശാലയിലേക്ക് മൈഗ്രേറ്റ് ചെയ്യുക തുടങ്ങി നിരവധി പണികൾ ബാക്കിയായിരുന്നു.
പദ്ധതിയിൽ അച്ചടി പുസ്തകങ്ങൾ താളിയോല അടക്കമുള്ള കൈയെഴുത്തുപ്രതികളും ഉണ്ടായിരുന്നു. അച്ചടി പുസ്തകങ്ങൾ എല്ലാം കോമൺസിലേക്ക് അപ്ലോഡ് ചെയ്തതോടെ യൂണിക്കോഡ് പതിപ്പ് മലയാളം വിക്കിഗ്രന്ഥശാലയിലേക്ക് മൈഗ്രേറ്റ് ചെയ്യുന്ന പരിപാടിയും തീർന്നു.
ഗുണ്ടർട്ട് ലെഗസി പദ്ധതിയിലെ അച്ചടി പുസ്തകങ്ങളുടെ പട്ടിക
ഇതിലെ ബുദ്ധിമുട്ട് പിടിച്ച പണി സ്കാനുകൾ ട്യൂബിങ്ങൻ സെർവ്വറിൽ നിന്ന് ഡൗൺലോഡ് ചെയ്ത്, പിന്നെ വിക്കിമീഡിയ കോമൺസിലേക്ക് അപ്ലൊഡ് ചെയ്യുന്നത് ആയിരുന്നു. റോജി പാല, ശ്രീജിത്ത് കെ., റസിമാൻ എന്നിവർ ചേർന്നാണ് ഈ ഡൗൺലോഡ് -അപ്ലോഡ് പരിപാടി ചെയ്തത്. ഫയലുകൾ എല്ലാം ഹെവി ആയിരുന്നതിനാൽ https://www.internetdownloadmanager.com/ എന്ന ടൂൾ ഉപയോഗിച്ചായിരുന്നു ഞാൻ ഡൗൺലോഡ് ചെയ്തത്. ഫയലുകൾ വിക്കിമീഡിയ കോമൺസിൽ എത്തിയതോടെ സെർവ്വർ സ്പീഡും മറ്റും മെച്ചമാണ് എന്നതിനാൽ ഇനി ഡൗൺലോഡിങ് എളുപ്പത്തിൽ നടക്കും.
വിക്കിഗ്രന്ഥശാലയിലേക്ക് മൈഗ്രേറ്റ് ചെയ്യുന്ന പണി ഏകദേശം ഒറ്റയ്ക്ക് റസിമാൻ ആണ് ചെയ്തത്. അവസാനം വിക്കിമീഡിയ കോമൺസിൽ നിന്ന് ലിങ്കുകൾ ശേഖരിച്ച് അടുക്കിപെറുക്കുന്ന പണി റോജി പാലയും ചെയ്തു. ഇത് എല്ലാം പൂർത്തിയായത് കൊണ്ടാണ് ഇപ്പോൾ ഈ പട്ടിക നിർമ്മിക്കാൻ പറ്റിയത്.
ഈ കാര്യത്തിൽ സഹകരിച്ച എല്ലാവർക്കും നിസ്സീമമായ നന്ദി.
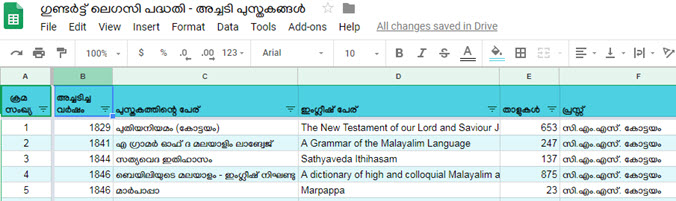
ഇപ്പോൾ അച്ചടി പുസ്തകങ്ങൾ എല്ലാം അപ്ലോഡ് ചെയ്യുകയും യൂണിക്കോഡ് പതിപ്പ് മൈഗ്രേറ്റ് ചെയ്യുകയും ചെയ്തതിനാൽ, ഉപയോഗിക്കുന്നവരുടെ സൗകര്യത്തിന്നു ഇതെല്ലാം കൂടെ സമാഹരിച്ച് ഒരു സ്പ്രെഡ് ഷീറ്റാക്കി പ്രസിദ്ധീകരിക്കുന്നു. താഴെ പറയുന്ന മൂന്നു ഷീറ്റുകൾ ആണ് പങ്കു വെക്കുന്നത്:
യൂണിക്കോഡിലാക്കിയ ലെറ്റർ പ്രസ്സ് അച്ചടി പുസ്തകങ്ങൾ (100 എണ്ണം)
യൂണിക്കോഡിലാക്കിയ കല്ലച്ചടി പുസ്തകങ്ങൾ (37 എണ്ണം)
യൂണിക്കോഡിലാക്കാത്ത ലെറ്റർ പ്രസ്സ്/കല്ലച്ചടി പുസ്തകങ്ങൾ (30 എണ്ണം)
ഇതിൽ ആദ്യത്തെ രണ്ട് പട്ടികയിൽ പുസ്തകത്തിന്റെ പേര്, പ്രസ്സ്, താളുകളുടെ എണ്ണം, ട്യൂബിങ്ങൻ ലൈബ്രറി ലിങ്ക്, ഡൗൺലൊഡ് സൈസ്, ഡൗൺലോഡ് ലിങ്ക്, വിക്കിഗ്രന്ഥശാല കണ്ണി (യൂണീക്കോഡ് പതിപ്പിനായി) എന്നിവ കൊടുത്തിരിക്കുന്നു. മൂന്നാമത്തെ പട്ടികയിൽ വിക്കിഗ്രന്ഥശാല കണ്ണി ഒഴിച്ച് (ആ പുസ്തകങ്ങൾ യൂണീക്കോഡ് ആക്കത്തതിനാൽ) ബാക്കി എല്ലാം ഉണ്ട്.
മൊത്തം 36,141 താളുകൾ ആണ് ഈ 167 പുസ്തകങ്ങളിൽ ഉള്ളത്. അതിൽ 25,592 താളുകൾ യൂണിക്കോഡാക്കി. ബാക്കി 10,549 താളുകൾ യൂണിക്കോഡാക്കുക എന്നത് വിക്കിഗ്രന്ഥശാലയിലും മറ്റു പ്രസ്ഥാനങ്ങളിലും ഉള്ള പ്രവർത്തകരുടെ ചുമതല ആണ്.
ഇതെല്ലാം കൂടെ ഡൗൺലോഡ് ചെയ്യാൻ നിന്നാൽ വലിയ പണിയാണ്. ആദ്യത്തെ പട്ടികയിലെ 100 പുസ്തകങ്ങൾ തന്നെ 22 GB വരും. രണ്ടാമത്തെ പട്ടികയിലെ 37 പുസ്തകങ്ങൾ ചേർന്ന് 9 GB വരും. മൂന്നമത്തെ പട്ടികയിലെ 30 പുസ്തകങ്ങൾ ചേർന്ന് 11 GB വരും. അതായത് ഈ 167 പുസ്തകങ്ങളും കൂടി 42 GB സൈസ് വരും. ഡൗൺലോഡ് ചെയ്യാൻ ഉദ്ദേശിക്കുന്നവർ https://www.internetdownloadmanager.com/ പോലുള്ള ടൂളുകൾ ഉപയോഗിച്ച് ഡൗൺലോഡ് ചെയ്യുന്നതാവും നല്ലത്. ഞാൻ അങ്ങനെ ചെയ്തപ്പൊഴേ വലിയ ഫയലുകൾ ഡൗൺലോഡ് ചെയ്യാൻ കഴിഞ്ഞുള്ളൂ. ഡൗൺലോഡ് ചെയ്യുന്നവർ വിക്കിമീഡിയ കോമൺസിന്റെ ഡൗൺലോഡ് കണ്ണി ഉപയോഗിക്കുന്നതാണ് നല്ലത്. അതിൽ നിന്നുള്ള ഡൗൺലോഡിങ് എളുപ്പം നടക്കും.
വിക്കിഗ്രന്ഥശാല കണ്ണി ഉപയോഗിച്ച് എത്തുന്ന ഒരു പുസ്തകത്തിന്റെ ഇൻഡെക്സ് പേജിൽ നിന്ന് ക്ലിക്ക് ചെയ്താൽ ഓരോ പേജിന്റെയും യൂണിക്കോഡ് പതിപ്പും കിട്ടും. യൂണിക്കോഡ് പതിപ്പ് ഒക്കെ ഉപയോഗിച്ച് പുനഃപ്രസിദ്ധീകരണം നടത്താനുള്ള വലിയ സാദ്ധ്യതയാണ് തുറന്നിരിക്കുന്നത്. അങ്ങനെ ചെയ്യുന്നവർ ട്യൂബിങ്ങൻ യൂണിവേഴ്സിറ്റിക്ക് തക്കതായ കടപ്പാട് രേഖപ്പെടുത്താനുള്ള സാമാന്യ മര്യാദ കാണിക്കും എന്ന് കരുതട്ടെ.
പതിവുപോലെ ഇത് സാദ്ധ്യമാക്കിയ ട്യൂബിങ്ങൻ യൂണിവേഴ്സിറ്റിക്കും പദ്ധതിയുമായി ബന്ധപ്പെട്ട എല്ലാവർക്കും നന്ദിയും കടപ്പാടും രേഖപ്പെടുത്തട്ടെ.
മൂന്നു പട്ടികകളും താഴെ കൊടുക്കുന്നു. വെറിക്കലായും ഹൊറിസോണ്ടലായും സ്ക്രോൾ ചെയ്താൽ ഒരോ പട്ടികയിലേയും എല്ലാം കോളങ്ങളും എല്ലാ റോകളും കാണാവുന്നതാണ്. (ഈ സ്പ്രെഡ് ഷീറ്റ് നേരിട്ട് ആക്സെസ് ചെയ്യാനുള്ള കണ്ണി ഇവിടെ)
യൂണിക്കോഡിലാക്കിയ ലെറ്റർ പ്രസ്സ് അച്ചടി പുസ്തകങ്ങൾ (100 എണ്ണം)
യൂണിക്കോഡിലാക്കിയ കല്ലച്ചടി പുസ്തകങ്ങൾ (37 എണ്ണം)
യൂണിക്കോഡിലാക്കാത്ത ലെറ്റർ പ്രസ്സ്/കല്ലച്ചടി പുസ്തകങ്ങൾ (30 എണ്ണം)

You must be logged in to post a comment.